
Physische Phase: Implementation des relationale Modells in ein DBS
Abschnittsübersicht
-
-
SQLite als gewähltes Datenbanksystem
Vor der Implementierung der Tabellen des relationalen Modells in ein Datenbanksystem wird jedem Attribut ein geeigneter Datentyp zugeordnet. Zusätzliche Angaben pro Attribut ermöglichen Einschränkungen des Wertebereichs und sorgen bei der Dateneingabe für Datenintegrität.
Datentypen
Wir unterscheiden zwischen den Datentypen (siehe auch SQLite-Dokumentation)
- INTEGER – vorzeichenbehaftete Ganzzahl, gespeichert in max. 8 Byte,
- REAL – vorzeichenbehaftete Gleitkommazahl, gespeichert in 8-Byte IEEE-Notation,
- TEXT – Zeichenkette, gespeichert als UTF-8, UTF-16 oder UTF-16LE-Wert,
- BLOB – Datenpaket, gespeichert wie eingegeben.
In SQLite können bei der Definition der Attribute auch Zeit-, Datums- oder boolesche Datentypen angegeben werden, diese wandelt das System intern in einen Ersatztyp um. Bei der Dateneingabe sind Schreibweisen einzuhalten.
- DATE – Ersatztyp TEXT in der Form 'YYYY-MM-DD'
- TIME – Ersatztyp TEXT in der Form 'HH:MM:SS'
- DATETIME – Ersatztyp TEXT in der Form 'YYYY-MM-DD HH:MM:SS'
- BOOLEAN – Ersatztyp INTEGER mit den Werten 0 und 1
Wertebereichsintegrität
Bei der Definition von Attributen sind Wertebereichseinschränkungen und Vorgabewerte möglich, beispielsweise
- NULL/Nicht NULL: NULL-Wert ist (nicht) zulässig,
- Eindeutigkeit (UNIQUE): Attributwert muss über alle Datensätze hinweg eindeutig sein,
- Standard (DEFAULT): Vorgabe eines Standardattributwertes, welches überschrieben werden kann,
- Zustandsprüfung (CHECK): Vorgabe einer Bedingung für den Wert in Analogie zur WHERE-Klausel bei SQL-Abfragen.
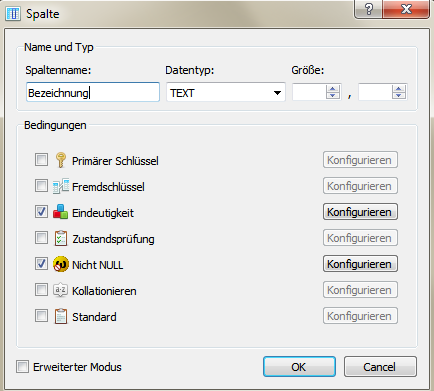
Bild: Festlegung der Attributeigenschaften in SQLiteStudioFestlegung von Primär- und Fremdschlüsseln
Besteht der Primärschlüssel aus genau einem Attribut, erfolgt diese Festlegung bei der Definition des Attributs durch die Option Primärer Schlüssel. Weitere Optionen (AUTOINCREMENT, Sortierung) sind möglich.
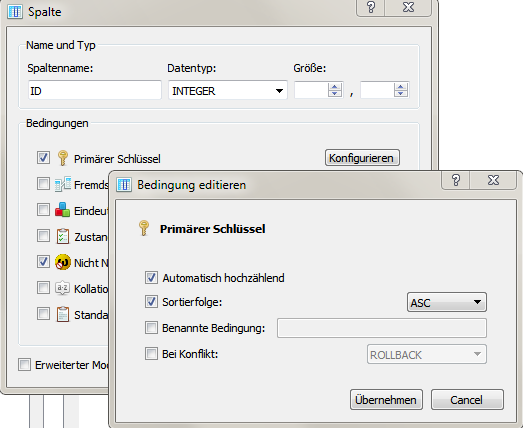
Bild: Festlegung zusätzlicher Primärschlüsseleigenschaften in SQLiteStudioLiegt ein zusammengesetzter Primärschlüssel vor, so sind die einzelnen Attribute ohne die Aktivierung der Option Primärer Schlüssel festzulegen. Im Anschluss muss man unter Bedingungen die Schlüsseleigenschaft festlegen.

Bild: Definition eines zusammengesetzten Primärschlüssels mittles Bedingungsdefinition in SQLiteStudioDie Festlegung eines Fremdschlüssels erfolgt bei der Attributdefinition. Dem Attribut wird als Verweis die fremde Tabelle (Bezeichnung Primärtabelle) mit dem Schlüsselattribut zugeordnet.
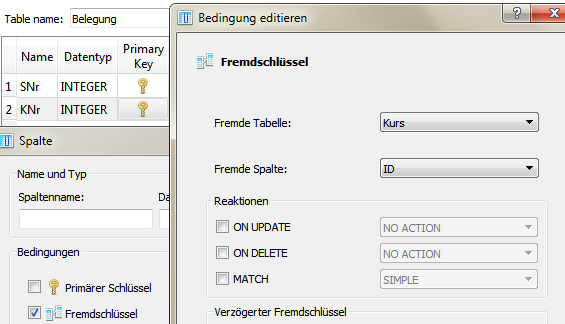
Bild: Festlegung der Fremdschlüsseleingeschaft und Setzen des Verweises in die Fremdtabelle in SQLiteStudioUnter Reaktionen sollte festgelegt werden, was beim Ändern/Löschen eines Datensatzes geschieht. Es gilt dabei:
- NO ACTION: Verweigerung aller Änderungen
- CASCADE: Weitergabe der Änderung/Löschung an die Detailtabelle
- RESTRICT: Verweigerung der Änderung auch in der Primärtabelle
- SET NULL/DEFAULT: Änderung des Verweises in der Detailtabelle auf NULL/DEFAULT, falls dort NULL/DEFAULT-Werte vorhanden/gestattet sind
-
02 Beispiel Zoo Lösung Datei
-