
Informatik 11 GK/LK: A Relationale Datenbanksysteme - Herr Hempel
Abschnittsübersicht
-
 Herzlich Willkommen im Kurs Informatik 11 A zum Thema Relationale Datenbanksysteme!
Herzlich Willkommen im Kurs Informatik 11 A zum Thema Relationale Datenbanksysteme!Sie werden im Thema Relationale Datenbanksysteme erfahren, wie Sie umfangreiche Datensammlungen effektiv erstellen und verwalten können. Die dabei notwendigen Handlungsschritte ermöglichen Ihnen einen Zugang zu Problemlösetechniken der Informatik.
Dieser Moodle-Kurs begleitet den Unterricht. Sie finden hier Tafelbilder, Aufgaben, Dateien, Arbeitsblätter sowie Lösungen. Die Unterlagen werden nach der Unterrichtsstunde freigegeben.
Stand: 25.11.2024 - Der Kurs ist aktuell nicht gepflegt.
-
-
Was assoziierst Du mit dem Begriff Informatik? Link/URL
-
Erstellen Sie mithilfe des Lehrbuchs Schöningh Informatik Bd. 1 Seite 6ff. und des Films "Was macht man im Informatik-Studium?" ein Pinnwand zur Beantwortung der Fragen
- Was ist Informatik?
- Wie ist die Wissenschaft der Informatik gegliedert?
- Womit beschäftigen sich die Teilgebiete der Informatik?
- Kennzeichnen Sie in der Pinnwand alle Bereiche, auf denen Sie im bisherigen Informatikunterricht schon einmal gearbeitet haben.
-
-
Richard Wossidlo gilt als Urvater der mecklenburgischen Volkskunde. Zeit seines Lebens sammelte er niederdeutsche Wörter, Redewendungen und Volksüberlieferungen. Wossidlo schrieb seine Daten auf Karten und sortierte sie in Karteikästen. Dieses Zettelkastensystem wurde mittlerweile von Informatikern digitalisiert und steht allen als Wossidlo-Archiv zur Verfügung.

Richard Wossidlo vor seinem Zettelkasten - Quelle: SchularchivFür die Digitalisierung mussten sich die Informatiker beispielsweise folgende Fragen stellen:
- Wie kann man einen Zettelkasten auf ein recherchefähiges Online-System umstellen?
- Wie lassen sich solche Datenmengen strukturieren?
- Wie kann man Informationen finden?
Eine Möglichkeit Daten strukturiert zu speichern, ist die Nutzung von Tabellen. In den Klassen 7 und 8 haben wir uns intensiv mit der Tabellenkalkulation beschäftigt und Daten in Tabellen verwaltet und Werte berechnet. Eine Tabellenkalkulationssoftware scheint also eine ideale Software zum Speichern und Verwalten großer Datenmengen zu sein.
Prüfen wir diese These anhand einer Bücherverwaltung.
-
Lösungen Arbeiten mit der Büchereiverwaltungsdatei Textseite
-
Beispiel
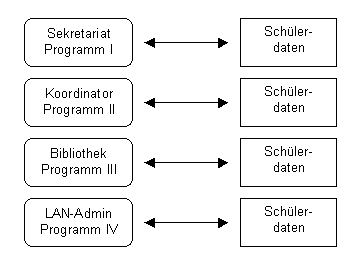
Für jeden Schüler werden jährlich die Stammdaten (Name, Vorname, Geburtsdatum, Anschrift, Telefon) erfasst bzw. kontrolliert. Die Eingabe der Daten erfolgt durch das Sekretariat. Die Grunddaten benötigen aber auch:
- der Koordinator der Sekundarstufe II, um das Kurssystem aufzubauen,
- der Koordinator der Sekundarstufe I, um die WPU-Kurse zu planen,
- die Schülerbibliothek, um die Leihlisten zu aktualisieren,
- der Schuladministrator, um die Schüleraccounts zu erstellen.
Jeder Verwender erhielt von allen Daten eine Kopie auf seinem Rechner. Damit konnte er auf diese zugreifen und Veränderungen in ihnen vornehmen. Ging ein Schüler vom Gymnasium ab, so konnte es passieren, dass seine Daten nur im Sekretariat gelöscht wurden. Die anderen Nutzer mit ihren veränderten Daten erfuhren nichts vom Abgang des Schülers.
Es ergab sich folgende Datennutzungsstruktur:
-
- Diskutieren Sie Nachteile der obigen Struktur. Leiten Sie Schlussfolgerungen ab.
- Beurteilen Sie die beiden Ansätze zur Speicherung von Daten einer Surfschule (S. 390f. Aufgabe 1-4) sowie eines Online-Buchhandels (S. 298). Leiten Sie Schlussfolgerungen für gute Datenbankensysteme ab.
-
Behauptung: Datenbanksystem bestehen aus einer Zwei-Schicht-Architektur und bieten exzellente Möglichkeiten zum Speichern und Verwalten umfangreicher Datenmengen.
Informieren Sie sich (in zwei Gruppen) im Lehrbuch Schöningh "Informatik 2" Kapitel 7.1 ab Seite 293 unten und 7.2 ab Seite 298 (ab Zwischenüberschrift ) bzw. im Lehrbuch HeLP "Datenbanken - Informatik für die Sekundarstufe II" Kapitel 2.1 über Datenbanksysteme. Ermitteln Sie Aspekte, die die Behauptungen untermauern. Stellen Sie diese unter Verwendung der u. g. Bereiche in einer Lernübersicht dar.
- Aufbau, Zugriff und Bestandteile (incl. Aufgaben der Teile) eines Datenbanksystems
- Anforderungen an Datenbanksysteme:
Datenkonsistenz, Datenintegrität, Redundanzarmut, Datensicherheit, Datenschutz, Mehrbenutzerbetrieb, Datenunabhängigkeit, zentrale Kontrolle
-
Nachteile einer solchen Datenverwaltung:
- starke Datenredundanz, d. h. dieselben Daten werden mehrfach gespeichert
- nach längerer Zeit erhöhte Dateninkonsistent, d. h. Widersprüchlichkeit zwischen den Datensammlungen
- Unflexibel beim Einarbeiten von Änderungen, d. h. Änderungen müssen für jeden Nutzer vorgenommen werden
- verminderter Datenschutz und geringe Datensicherheit, d. h. Nutzer erhalten Daten, deren Einsicht für sie nicht zulässig ist, Datendiebstahl wird vereinfacht
- keine Standards, d. h. jedes Programm verwaltet die Daten anders
Datenverwaltung optimal/heute
In der vernetzten Schule gibt es die Schülerdaten nur einmal. Die einzelnen Anwender/Programme greifen nach Prüfung der Befugnis über das Datenbankmanagementsystem (DBMS) logisch auf die Datenbasis zu und erhalten eine eingeschränkte, auf ihre Aufgaben zugeschnittene Sicht auf die Daten. Eine direkte Manipulation der Daten ist nicht mehr möglich. Das DBMS überwacht die Zugriffe.

Ein solcher Aufbau ist sinnvoll und dient als Modell für den allgemeinen Aufbau eines Datenbanksystems.
Grundsätzlicher Aufbau von Datenbanksystemen
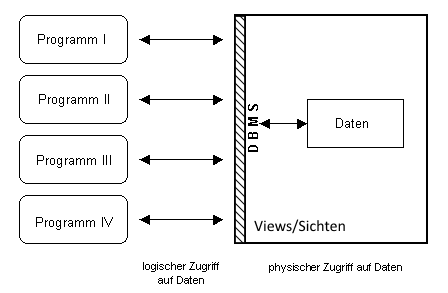
Ein Datenbanksystem (DBS) setzt sich aus einer Datenbasis und einem Datenbank-Managementsystem (DBMS) zusammen. Das DBMS ist ein Softwaresystem zur Definition, Administration, Manipulation und Abfrage von Daten. Es stellt die Schnittstelle zwischen Benutzer und Datenbasis dar und dient der effizienten Speicherung und Abfrage der strukturierten Daten. Die Datenbasis enthält neben den reinen Nutzdaten auch die zur Verwaltung des gesamten Systems nötigen Metadaten.
Kriterien/Anforderungen an DBS
Aus dem formalen Aufbau von Datenbanksystemen ergeben sich Eigenschaften, die gleichzeitig Kriterien für ein gute DBS sind:
- Integritätssicherung
Daten werden bereits während der Eingabe auf Korrektheit überprüft und Fehleingaben verhindert - Redundanzarmut
ungeordnete Mehrfachspeicherung von Datenwerten wird vermieden - Datensicherheit
ungewollter Datenverlust wird durch Backup- und Prüfmechanismen verhindert - Datenschutz
Zugriffskontrolle und spezifische Sichten sorgen für einen Zugang gemäß der Rechte des Nutzers - Mehrbenutzerbetrieb
mehrere Benutzer können parallel mit den Daten der Datenbank arbeiten, Kollisionen werden verhindert - Datenunabhängigkeit
das DBMS ist nicht an die Daten der Datenbank gekoppelt, es kann unabhängig von den Daten weiterentwickelt werden - zentrale Kontrolle
ein Administrator ist in der Lage, das gesamte System von einem Rechner aus zu verwalten
nach Horn/Kerner/Forbrig: Lehr- und Übungsbuch Informatik Bd. 1
-
 Die Aufgabe mit der Bibliotheksverwaltung hat ergeben, das sich die Daten in Tabellen strukturieren lassen. Diese Art der Modellierung wird relationales Datenbankmodell genannt und geht auf die Arbeit von Edgar F. Codd (Turing-Preisträger 1981) bei IBM aus dem Jahr 1970 zurück. Folgende Begriffe prägen das Modell:
Die Aufgabe mit der Bibliotheksverwaltung hat ergeben, das sich die Daten in Tabellen strukturieren lassen. Diese Art der Modellierung wird relationales Datenbankmodell genannt und geht auf die Arbeit von Edgar F. Codd (Turing-Preisträger 1981) bei IBM aus dem Jahr 1970 zurück. Folgende Begriffe prägen das Modell:
Das Relationenschema lässt sich kurz notieren: Person (PNr, Name, Vorname, PLZ, Ort)
Ziel des Kurses ist es, solche Strukturen aus Datenbankanforderungen selbst zu entwickeln. Zuvor wollen wir aber mal schauen, ob das Datenbanksystem wirklich besser in der Lage ist, Informationen aus den Tabellen zu ermitteln. Wir erinnern uns ja mit Grausen an die Bibliotheksaufgabe zurück!
Bild: (c) IBM, Quelle Wikipedia, https://en.wikipedia.org/wiki/File:Edgar_F_Codd.jpg
-
-
-
Bearbeiten wir das Hauptproblem bei der Verwaltung von Daten in Tabellen, nämlich die Frage: Wie kommen wir gezielt an Informationen. Das Datenbankmanagementsystem verfügt dazu über eine mächtige Sprache: SQL - und die lernen wir nun (erstmal spielerisch). Auf geht es nach SQL Island!
-
Lösungen SQL-Island Datei
-
Lösungen SQL-Island (Video) Link/URL
-
 Die Kommunikation mit dem Datenbanksystem erfolgt mithilfe der Programmiersprache SQL.
Die Kommunikation mit dem Datenbanksystem erfolgt mithilfe der Programmiersprache SQL.Diese Sprache wurde in den 1970er Jahren von Donald D. Chamberlin (ACM Software System Award 1988) und Raymond F. Boyce basierend auf den Arbeiten von Edgar F. Codd (Turing Award 1981) bei IBM im Rahmen eines Forschungsprojektes entwickelt und 1987 international standardisiert. Im Gegensatz zu bisher im Unterricht behandelten Programmiersprachen die eine Schrittfolge zur Lösung eines Problems angeben (imperative Sprache), ist SQL eine beschreibende (= deklarative) Sprache.
SQL-Befehle werden in verschiedene Klassen eingeteilt. Für den Informatikunterricht sind relevant:
- DDL – Data Definition Language
Befehle zur Definition von Tabellen und Sichten - DML – Data Manipulation Language
Befehle zur Datenmanipulation und Datenabfrage
Da wir fertige Datenbanksysteme nutzen wollen, ist zunächst nur die Datenabfrage interessant für uns.
Bild: CC BY-SA 4.0, Dicklyon, https://commons.wikimedia.org/wiki/File:Don_Chamberlin.jpg
- DDL – Data Definition Language
-
Ergänzen Sie das Arbeitsblatt zu den Operationen der Relationenalgebra Selektion, Projektion und Join mithilfe des Lehrbuchs Schöningh Informatik II, Kapitel 7.3.
-
02 AB Relationenalgebra Lösung Datei
-
01 Uni-Aufgabe 1 Lösungen Datei
-
01 Aufgabe Teil 2 Lösung modifiziert (LK) Datei
-
02 Übungen zur Relationenalgebra Lösung Datei
-
03 Lösungen DB-Lehrbuch S. 64/2 Datei
-
-
-
 In den bisherigen Stunden haben wir Datenbanken analysiert und aus ihnen Daten abgefragt. Wir wollen nun einen Schritt weiter gehen und selbst Datenbanken entwickeln. Liegt bereits eine Datensammlung vor, die erweitert oder angepasst werden soll, bietet sich der Prozess der Normalisierung an. Dabei werden die vorhandenen Strukturen analysiert und ggf. so umgestellt, das eine wohlstrukturierte und redundanzarme Datenbank entsteht. Der Prozess der Normalisierung geht auf die Arbeit von Edgar F. Codd zurück.
In den bisherigen Stunden haben wir Datenbanken analysiert und aus ihnen Daten abgefragt. Wir wollen nun einen Schritt weiter gehen und selbst Datenbanken entwickeln. Liegt bereits eine Datensammlung vor, die erweitert oder angepasst werden soll, bietet sich der Prozess der Normalisierung an. Dabei werden die vorhandenen Strukturen analysiert und ggf. so umgestellt, das eine wohlstrukturierte und redundanzarme Datenbank entsteht. Der Prozess der Normalisierung geht auf die Arbeit von Edgar F. Codd zurück.Probleme in nicht normalisierten Tabellen
Schauen wir uns aber zunächst an einem Beispiel an, welche Probleme in Datensammlungen auftreten können, die nicht normalisiert wurden.
Eine Schule verwaltet Lernangebote in der folgenden Relation:
SNr Name Vorname Klasse Klassenlehrer LANr Beschreibung Stunden 1 Jürgens Ina 11a Lempel 2 Tanz 12 2 Schmidt Tom 12a Breier 2, 3 Tanz, Chor 22, 8 3 Jäger Franz 11a Lempel 1, 2, 3 Elektronik, Tanz, Chor 15, 12, 2 4 Olsen Ina 11b Sommer 2 Tanz 5 5 Jürgens Paula 12a Breier 4 Töpfern 23 Welche Auswirkungen auf die Datenintegrität (Widerspruchsfreiheit) hat ...
- das Einfügen des neuen Kurses "3D-Druck":
→ Dies ist derzeit nicht möglich, da SNr Schlüssel ist. Der Kurs muss also durch einen Schüler belegt sein, um ihn einzufügen. - der Abgang/das Löschen der Schülerin Nr. 5 Paula Jürgens:
→ Dies hat zur Folge, dass neben den Schülerdaten auch die Daten des Töpferkurses gelöscht werden. - das Ändern des Namens wegen Heirat der Lehrerin Lempel zu Lempel-Schmidt:
→ Dies muss in der Tabelle mehrfach geändert werden. Dabei besteht die Gefahr der Dateninkonsistenz.
Das Ändern, Einfügen und Löschen von Daten kann also zu Problemen und Fehlern führen. Man bezeichnet dies als Änderungs- Einfüge-, Löschanomalie. Außerdem sind in der Tabelle Daten unnötigerweise mehrfach gespeichert. Die geforderte Redunandzarmut ist nicht gegeben.
- das Einfügen des neuen Kurses "3D-Druck":
-
Prozess der Normalisierung
Um Redundanzen zu minimieren und die Datenintegrität zu erhalten, werden die Relationen schrittweise in die sog. 3. Normalform überführt. In unserem Fall liegt nur die Relation Lernangebotsübersicht vor:
SNr Name Vorname Klasse Klassenlehrer LANr Beschreibung Stunden 1 Jürgens Ina 11a Lempel 2 Tanz 12 2 Schmidt Tom 12a Breier 2, 3 Tanz, Chor 22, 8 3 Jäger Franz 11a Lempel 1, 2, 3 Elektronik, Tanz, Chor 15, 12, 2 4 Olsen Ina 11b Sommer 2 Tanz 5 5 Jürgens Paula 12a Breier 4 Töpfern 23 1. Normalform
Eine Relation befindet sich in der ersten Normalform, falls alle Attribute atomaren Werte aufweisen.
Zur Bildung der ersten Normalform müssen die nicht atomaren Attributwerte durch Einfügen zusätzlicher Zeilen, Spalten oder neuer Relationen aufgeteilt werden.
Relation Lernangebotsübersicht kann durch Hinzufügen von Zeilen (oder durch Auslagern der nichtatomaren Attribute mit dem vorhandenen Schlüssel) in eine neue Relation in die erste Normalform überführt werden:
SNr Name Vorname Klasse Klassenlehrer LANr Beschreibung Stunden 1 Jürgens Ina 11a Lempel 2 Tanz 12 2 Schmidt Tom 12a Breier 2 Tanz 22 2 Schmid Tom 12a Breier 3 Chor 8 3 Jäger Franz 11a Lempel 1 Elektronik 15 3 Jäger Franz 11a Lempel 2 Tanz 12 3 Jäger Franz 11a Lempel 3 Chor 2 4 Olsen Ina 11b Sommer 2 Tanz 5 5 Jürgens Paula 12a Breier 4 Töpfern 23
Beobachtung: Die Redundanz nimmt zu. Der bisherige Primärschlüssel verliert seine Eindeutigkeit.2. Normalform
Eine Relation befindet sich in der zweiten Normalform, falls
-
- die Relation in der ersten Normalform ist und
- jedes Nichtschlüsselattribut vom Primärschlüssel voll funktional abhängig ist.
Regel zum Prüfen der zweiten Bedingung:
Wenn Nichtschlüsselattribute von einem Teil des Schlüssels eindeutig identifiziert werden, dann liegt keine 2. Normalform vor!Schrittfolge zur Herstellung der zweiten Normalform:
-
- Festlegen/Feststellen des Primärschlüssel
→ Falls dieser nur aus einem Attribut besteht, so liegt 2. NF vor. - Untersuchen, ob aus Teilschlüsselattributen bereits weitere Attribute folgen.
→ Falls dies nicht der Fall ist, so liegt die 2. NF vor.
→ Falls dies der Fall ist, so Schritt 3. - Bilden einer neuen Relation. Diese enthält das Teilschlüsselattribut und alle von ihm abhängigen Nichtschlüsselattribute. Das Teilschlüsselattribut wird in der neuen Relation der Primärschlüssel.
- Löschen der ausgelagerten Nichtschlüsselattribute in der Ausgangsrelation.
- Wiederholen des Vorgangs ab Schritt 2, bis alle Nichtschlüsselattribute vom gesamten Schlüssel funktional abhängig sind.
- Festlegen/Feststellen des Primärschlüssel
In der Relation Lernangebotsübersicht ist die Attributkombination SNr und LANr der neue Primärschlüssel. Aus dem Teilschlüssel LANr lässt sich bereits eindeutig auf das Attribut "Beschreibung" schließen. Aus SNr lässt sich eindeutig auf die Attribute "Name", "Vorname", "Klasse" und" Klassenlehrer" schließen. Somit sind zwei neue Relationsschemen Lernangebot und Schüler zu erzeugen und das verbleibende Schema Lernangebotsübersicht so zu überarbeiten, dass die Attribute "Beschreibung", "Name", "Vorname", "Klasse" und "Klassenlehrer" gelöscht werden.

Relation Lernangebot Relation Schüler Relation Lernangebotsübersicht LANr Beschreibung 1 Elektronik 2 Tanz 3 Chor 4 Töpfern SNr Name Vorname Klasse Klassenlehrer 1 Jürgens Ina 11a Lempel 2 Schmidt Tom 12a Breier 3 Jäger Franz 11a Lempel 4 Olsen Ina 11b Sommer 5 Jürgens Paula 12a Breier ↑Nr ↑LANr Stunden 1 2 12 2 2 22 2 3 8 3 1 15 3 2 12 3 3 2 4 2 5 5 4 23 3. Normalform
Eine Relation befindet sich in der dritten Normalform, falls
-
- die Relation in der zweiten Normalform ist und
- zwischen den Nichtschlüsselattributen keine Abhängigkeiten existieren, d. h. aus keinem Nichtschlüsselattribut folgt ein anderes Nichtschlüsselattribut (Fachbegriff: keine transitiven Abhängigkeiten)
Regel zum Prüfen der zweiten Bedingung:
Wenn aus einem Nichtschlüsselattribut ein anderes Nichtschlüsselattribut folgt, dann liegt keine 3. Normalform vor!Schrittfolge zur Herstellung der dritten Normalform:
-
- Untersuchung, ob aus Nichtschlüsselattributen andere Nichtschlüsselattribute folgen.
→ Falls dies nicht der Fall ist, so liegt bereits die 3. NF vor.
→ Falls dies der Fall ist, so Schritt 3. - Bilden einer neuen Relation. Diese enthält das Nichtschlüsselattribut und die von ihm abhängigen Attribute. Das Nichtschlüsselattribut wird in der neuen Relation der Primärschlüssel.
- Löschen der ausgelagerten Nichtschlüsselattribute mit Ausnahme des Attributes, das in der neuen Relation Primärschlüssel ist.
- Wiederholen des Vorgangs ab Schritt 1, bis keine Abhängigkeiten mehr bestehen.
- Untersuchung, ob aus Nichtschlüsselattributen andere Nichtschlüsselattribute folgen.
In den Relation Lernangebotsübersicht und Lernangebot gibt es nur ein Nichtschlüsselattribut. Daher liegen die Tabellen in der 3. NF vor. In der Relation Schüler folgt aus dem Nichtschlüsselattribut "Klasse" jedoch der "Klassenlehrer". Somit ist eine neue Relation Klassenübersicht mit den Attributen "Klasse" (Primärschlüssel) und "Klassenlehrer" zu erzeugen und das verbleibende Schema Schüler so zu überarbeiten, dass das Attribut "Klassenlehrer" gelöscht wird.

Relation Lernangebot Relation Schüler Relation Lernangebotsübersicht Relation Klassenübersicht LANr Beschreibung 1 Elektronik 2 Tanz 3 Chor 4 Töpfern SNr Name Vorname ↑Klasse 1 Jürgens Ina 11a 2 Schmidt Tom 12a 3 Jäger Franz 11a 4 Olsen Ina 11b 5 Jürgens Paula 12a ↑SNr ↑LANr Stunden 1 2 12 2 2 22 2 3 8 3 1 15 3 2 12 3 3 2 4 2 5 5 4 23 Klasse Klassenlehrer 11a Lempel 11b Sommer 12a Breier -
-
01 AB Normalisierung Lösungen Datei
-
01 Normalisierungsablauf Lösung Datei
-
-
-
Etappen für den Entwurf eines Datenbanksystems
Die systematische Entwicklung eines Datenbanksystems erfolgt in Schritten, deren korrekte Ausführung maßgeblich über die Qualität des Endprodukts entscheidet. Im Allgemeinen ist folgender Ablauf notwendig:
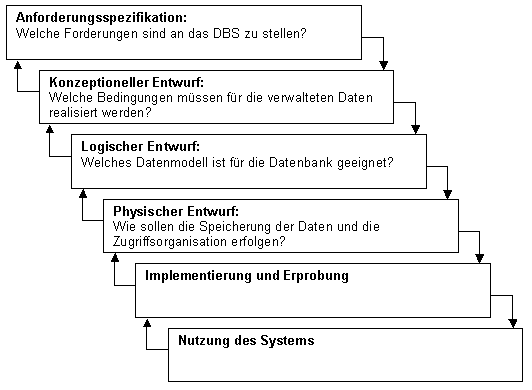
Diese Schritte werden gern in drei Phasen/Etappen zusammengefasst.
Anforderungsspezifikation und
konzeptionelle Entwurfsetappe→
logische Entwurfsetappe
→
physischer Entwurf und Implementierung
- IST-Analyse
- SOLL-Konzept (Erstellung eines Profils für die Anforderungen an das DBS)
- Abbildung des erforderlichen Realitätssausschnitts entsprechend der Anforderungen und Bedingungen unabhängig vom DBMS in eine grafische Darstellung durch die Abstraktion von Objekten und deren Beziehung zueinander auf Entitätstypen und Beziehzungstypen
- Umwandlung des ER-Modells in das relationale Datenmodell mithilfe eines Regelsystems
- Festlegung von Primärschlüssel- und Fremdschlüsselattributen
- Festlegung der Datentypen der Attribute ggf. mit weiteren Einschränkungen zur Sicherstellung der Integrität und Konsistenz
- Festlegung von Sichten und Zugriffsrechte zur Sicherstellung des Datenschutzes und der Datensicherheit
- Implementation im DBMS
- Eingaben von Grunddaten
Entity-Relationship-Modell (ER-Modell)
relationales Modell
RelationenschemaDatenbanksystem
-
-
 Die Modellierung mithilfe des Entity-Relationship-Modells wurde 1976 vom taiwanischer Informatiker Peter Chen entwickelt. Dieses Modell ist die Grundlage für Analyse- und Design-Methoden in der Entwicklung von Datenbanken und Software. Chen zählt zu den Pionieren der Informatik.
Die Modellierung mithilfe des Entity-Relationship-Modells wurde 1976 vom taiwanischer Informatiker Peter Chen entwickelt. Dieses Modell ist die Grundlage für Analyse- und Design-Methoden in der Entwicklung von Datenbanken und Software. Chen zählt zu den Pionieren der Informatik.Fotolink aus der Website von Peter Chen als Person der Zeitgeschichte: https://bit.csc.lsu.edu/~chen/chen.html
-
Entität, Attribut, Attributwert, Entitätstyp und Schlüssel
Eine Entität ist ein eindeutig identifizierbares Objekt oder ein eindeutig identifizierbarer Sachverhalt, beispielsweise
- der Schüler Karl Meier aus der Klasse 7a,
- mein Fahrrad der Marke Mifa,
- ein Exemplar des Buches "Abenteuer Informatik" mit der ISBN 978-38274-1635-3,
- Konrad Zuses Computer Z3.
Jede Entität wird durch Attribute/Eigenschaften mit ihren Werten beschrieben. Ein Attribut, dessen Wert zu einem Zeitpunkt unbestimmt/unbekannt ist, besitzt einen NULL-Wert.
Entität: Schüler Karl Meier aus der Klasse 7a
Attribut mit Wert: Name = Meier, Vorname = Karl, Wohnort = Hohenwulsch, Schule = Dorfschule, Klasse = 7a, Telefon = NULL, ...Ein Entitätstyp ist eine abstrakte Beschreibung einer Menge von Entitäten mit gleichen Attributen. Eine Entität ist ein eindeutig identifizierbares Element des Entitätstyps. Ein Entitätstyp wird durch die Angabe des Namens und der Attribute vollständig beschrieben.
Karl Meier könnte eine Entität des Entitätstyps Schüler sein.
Seine Attribute Name und Vorname werden durch die Werte Meier bzw. Karl belegt.Objektorientierte Darstellung: Schüler.Name = "Meyer"
Im Entity-Relationship-Diagramm (ER-Diagramm) wird der Entitätstyp durch Rechteck dargestellt und beschriftet. Die Attribute werden i. d. R. durch Ovale dargestellt, die eine Verbindung zum Entitätstyp haben.

Besonderheiten bei Attributen:
- (Teil-) Schlüsselattribut – Unterstreichung:
Ein Schlüssel ist eine minimale Kombination von Attributen, durch deren Werte jede Entität eindeutig identifiziert wird. Die Werte können sich während der Existenz der Entität unter bestimmten Bedingungen ändern, die Eindeutigkeit muss dabei stets gewahrt bleiben. Wird ein Attribut zur Identifikation benötigt, spricht man von einem einfachen Schlüssel. Ansonsten spricht man vom zusammengesetzten Schlüssel, jedes Attribut bezeichnet man als Teilschlüsselattribut. - Zusammengesetztes Attribut – Verbindung von Attribut zu Attribut:
Ein Attribut besteht aus weiteren Eigenschaften, beispielsweise die Anschrift aus PLZ, Ort, Straße und Hausnummer.
Beziehung, Beziehungstyp und Kardinalität
Zwischen Entitäten können vielfältige Beziehungen bestehen, beispielsweise kann Lehrer Lempel der Klassenlehrer des Schülers Paul Meyer sein. Eine Beziehungen besteht zwischen mindestens zwei Entitäten und ist immer gerichtet. Für das Beispiel gilt dann:
Richtung 1: der Lehrer Lempel unterrichtet den Schüler Karl Meyer.
Richtung 2: der Schüler Karl Meyer wird von Lehrer Lempel unterrichtet.Eine Beziehung verbindet eine oder mehrere Entitäten miteinander. Assoziieren stets zwei Entitäten miteinander, so spricht man von binärer Beziehung. Ein Beziehungstyp umfasst alle Beziehungen, die gleichartig und wechselseitig zwischen zwei Entitätstypen bestehen. Ein Beziehungstyp kann Attribute besitzen. Ob ein Sachverhallt unserer Welt eine Entität oder Beziehung ist, steht oft nicht fest. Hier muss der Datenbankmodellierer angemessen entscheiden. Für die Darstellung von Beziehungstypen nutzt man das Rautensymbol und notiert darin den Namen des Beziehungstyp – möglichst als Verb.

Die Kardinalität trifft eine Aussage über die maximale Anzahl der an einer Beziehung beteiligten Entitäten. Für die Datenstrukturierung interessieren nicht die genauen Zahlen, sondern nur die Angaben "höchstens eine Entität (1)" oder "mehrere Entitäten (n oder m)". Da der Beziehungstyp wechselseitig ist, wird die Kardinalität durch zwei Angaben vollständig beschrieben.
a) Jeder Schüler geht in höchstens eine Klasse.
b) Jede Klasse besteht aus mehreren Schülern.
Es gibt drei Kombinationen, die wir in der Chen-Notation angeben:
- 1:1: Jeder Raum ist Klassenraum für höchstens ein Klasse. Jede Klasse hat höchstens einen Raum als Klassenraum.

- 1:n: Jeder Schüler geht in höchstens eine Klasse. Jede Klasse besteht aus mehreren Schülern.

- n:m: Jeder Lehrer unterrichtet mehrere Klassen. Jede Klasse wird von mehreren Lehrern unterrichtet.

-
Auswertung Begriffspuzzle Datei
-
Lösung Datei
-
-
-
01 Maschinenverleih Lösung Datei
-
04 Lösungen Datei
-
-
SQLite als gewähltes Datenbanksystem
Vor der Implementierung der Tabellen des relationalen Modells in ein Datenbanksystem wird jedem Attribut ein geeigneter Datentyp zugeordnet. Zusätzliche Angaben pro Attribut ermöglichen Einschränkungen des Wertebereichs und sorgen bei der Dateneingabe für Datenintegrität.
Datentypen
Wir unterscheiden zwischen den Datentypen (siehe auch SQLite-Dokumentation)
- INTEGER – vorzeichenbehaftete Ganzzahl, gespeichert in max. 8 Byte,
- REAL – vorzeichenbehaftete Gleitkommazahl, gespeichert in 8-Byte IEEE-Notation,
- TEXT – Zeichenkette, gespeichert als UTF-8, UTF-16 oder UTF-16LE-Wert,
- BLOB – Datenpaket, gespeichert wie eingegeben.
In SQLite können bei der Definition der Attribute auch Zeit-, Datums- oder boolesche Datentypen angegeben werden, diese wandelt das System intern in einen Ersatztyp um. Bei der Dateneingabe sind Schreibweisen einzuhalten.
- DATE – Ersatztyp TEXT in der Form 'YYYY-MM-DD'
- TIME – Ersatztyp TEXT in der Form 'HH:MM:SS'
- DATETIME – Ersatztyp TEXT in der Form 'YYYY-MM-DD HH:MM:SS'
- BOOLEAN – Ersatztyp INTEGER mit den Werten 0 und 1
Wertebereichsintegrität
Bei der Definition von Attributen sind Wertebereichseinschränkungen und Vorgabewerte möglich, beispielsweise
- NULL/Nicht NULL: NULL-Wert ist (nicht) zulässig,
- Eindeutigkeit (UNIQUE): Attributwert muss über alle Datensätze hinweg eindeutig sein,
- Standard (DEFAULT): Vorgabe eines Standardattributwertes, welches überschrieben werden kann,
- Zustandsprüfung (CHECK): Vorgabe einer Bedingung für den Wert in Analogie zur WHERE-Klausel bei SQL-Abfragen.
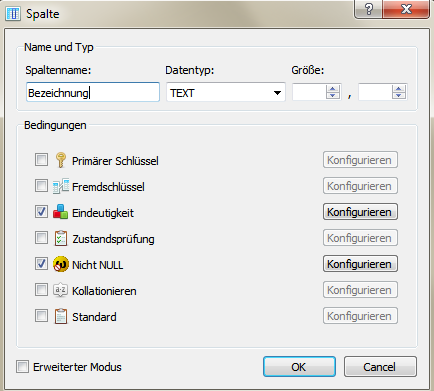
Bild: Festlegung der Attributeigenschaften in SQLiteStudioFestlegung von Primär- und Fremdschlüsseln
Besteht der Primärschlüssel aus genau einem Attribut, erfolgt diese Festlegung bei der Definition des Attributs durch die Option Primärer Schlüssel. Weitere Optionen (AUTOINCREMENT, Sortierung) sind möglich.
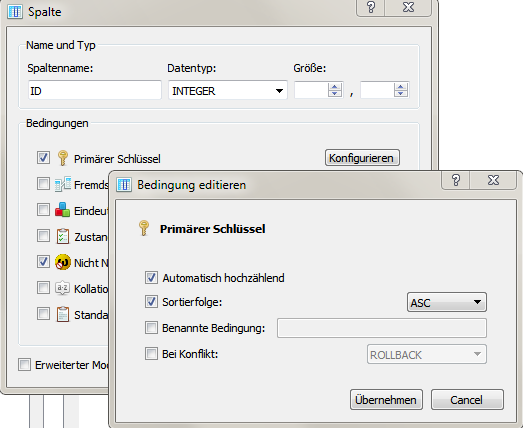
Bild: Festlegung zusätzlicher Primärschlüsseleigenschaften in SQLiteStudioLiegt ein zusammengesetzter Primärschlüssel vor, so sind die einzelnen Attribute ohne die Aktivierung der Option Primärer Schlüssel festzulegen. Im Anschluss muss man unter Bedingungen die Schlüsseleigenschaft festlegen.

Bild: Definition eines zusammengesetzten Primärschlüssels mittles Bedingungsdefinition in SQLiteStudioDie Festlegung eines Fremdschlüssels erfolgt bei der Attributdefinition. Dem Attribut wird als Verweis die fremde Tabelle (Bezeichnung Primärtabelle) mit dem Schlüsselattribut zugeordnet.
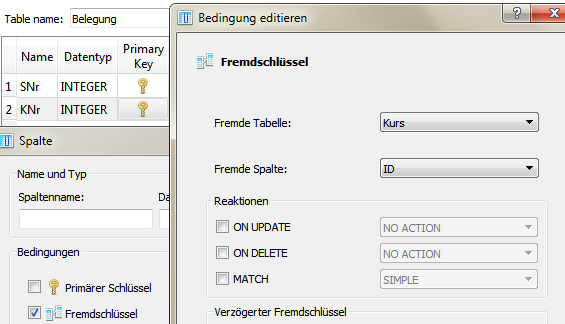
Bild: Festlegung der Fremdschlüsseleingeschaft und Setzen des Verweises in die Fremdtabelle in SQLiteStudioUnter Reaktionen sollte festgelegt werden, was beim Ändern/Löschen eines Datensatzes geschieht. Es gilt dabei:
- NO ACTION: Verweigerung aller Änderungen
- CASCADE: Weitergabe der Änderung/Löschung an die Detailtabelle
- RESTRICT: Verweigerung der Änderung auch in der Primärtabelle
- SET NULL/DEFAULT: Änderung des Verweises in der Detailtabelle auf NULL/DEFAULT, falls dort NULL/DEFAULT-Werte vorhanden/gestattet sind
-
02 Beispiel Zoo Lösung Datei
-
02 Beispiel Zoo Datei
-
-
-
Hinweis für Nachnutzer: Für den Einsatz im Unterricht muss eine Vorführlizenz bei Schulfilme-Online erworben werden.
-
01 AB Schutz Sicherheit Lösung Datei